
Um die Dunkelziffer aller am Coronavirus erkrankten Österreicherinnen und Österreicher abzuschätzen, wurde eine Zufallsstichprobe von 2000 Menschen in Österreich durchgeführt, wovon in etwa 1500 mitgemacht haben. Diese hat einen Prozentsatz von 0,33%, sprich 5 coronaviruskranken Personen gefunden. Aufgrund dieses Ergebnisses kann man ein 95%iges Konfidenzband, von etwa 10.200 bis 76.400 für die tatsächlich an Coronavirus Erkrankten in Österreich bestimmen. Ich berufe mich hier auf die Zahlen laut Kurier.
Für diese Konfidenzintervallsberechnung werden ausschließlich die Daten aus dieser Stichprobe verwendet. Mein Vater, Helmut Kuzmics, hat mich gefragt, ob das nicht etwas seltsam ist und ob man das, gegeben das ganze andere Wissen, das man hat, nicht vielleicht stärker einschränken könnte? Oder könnte man nicht vielleicht die Stichprobe anders wählen, um zum Beispiel dem gerecht zu werden, dass in Ischgl viel mehr Fälle bekannt sind als in einer ähnlich großen Gemeinde im Burgenland? Mit einer allgemeinen Stichprobe dieser Art ist es ja leicht möglich, dass keine Person in Ischgl überhaupt in ihr enthalten ist.
Mein Vater hat recht. Man kann das besser machen, wenn man weiß, wie man das Wissen, das man schon hat, nutzen kann. Wie das funktionieren soll, erkläre ich hier anhand eines Gedankenexperiments. Ich habe für diesen Blogeintrag auch von Diskussionen mit Michael Greinecker profitiert.
Man könnte das Problem von vielen Seiten aus angehen. Sehr eignen würde es sich, hier einen (echten) Bayesianischen Statistikzugang zu verfolgen. BayesianerInnen hätten eine Vermutung über die Dunkelziffer sowie über die generelle geografische Verteilung von Coronakranken in Form eines sogenannten “priors” (einer Wahrscheinlichkeitsverteilung über all diese Dinge), die mit den schon bestehenden Daten sowie einem Verständnis der epidemiologischen Modelle konsistent wäre. Es wäre allerdings ein wenig mühsam, den Bayesianischen Zugang hier gut und knapp zu erklären. Ich kann das Problem aber auch sehr gut anhand der klassischen Statistik erklären, und zwar so, dass es, glaube ich, nachvollziehbarer ist.
Nun gleich zum Gedankenexperiment. Ich sollte vorher aber noch eine wichtige Unterscheidung machen. Ich spreche im weiteren Verlauf von zwei verschiedenen Verfahren mit denen man feststellt, ob eine Person den Coronavirus hat. Zum einen gibt es das, was ich die gängige Methode nenne, und zum anderen die Stichprobe. Die gängige Methode ist die, wie eine Person zurzeit zu den gemeldeten „positiv Getesteten“ (wie zum Beispiel auf dieser ORF Webseite) dazugezählt wird. Ich weiß nicht genau, wie diese gängige Methode funktioniert, aber ich stelle sie mir in etwa wie folgt vor: Zuerst muss man wohl 1450 anrufen. Dann beschreibt man die Symptome, die man hat, und wo man in letzter Zeit war und so weiter. Daraufhin wird entschieden, ob man überhaupt medizinisch getestet wird. Wenn ja und wenn dann der medizinische Test positiv ist, wird man schlussendlich als „positiv getestet“ gezählt. Die Stichprobe funktioniert anders. Hier wird man zufällig ausgewählt (oder halt nicht) und dann, egal was man für Symptome usw. hat, wird man medizinisch getestet.
Nun kann ich tatsächlich mit meinem Gedankenexperiment beginnen. Angenommen, wir wüssten, dass die gängige Methode bisher in allen Regionen nach den gleichen Richtlinien durchgeführt wurden (nach der Art der Symptome, der Anzahl der Kontakte, und so weiter). Aus dieser Annahme würde sich ergeben, dass die Dunkelziffer proportional zu den gemeldeten Coronakranken wäre, und zwar mit demselben Proportionalitätsfaktor für alle Regionen. Das ist übrigens auch eine Annahme, die man grundsätzlich empirisch überprüfen kann. Und wenn das nun so wäre, dann wäre es tatsächlich sinnvoller, eine Stichprobe in der Region zu machen, die die meisten gemeldeten Fälle hat, anstatt eine große österreichweite Stichprobe zu ziehen.
Ich finde das auch intuitiv recht einleuchtend, aber richtig erklären, also eigentlich beweisen, kann ich das nur anhand von ein bisschen Mathematik.
Nennen wir die Wahrscheinlichkeit, dass eine Person in einer bestimmten Region am Coronavirus erkrankt ist, 


Nun schreiben wir 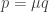



Also sagen wir, wir führen eine Stichprobe von 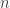
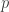
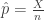

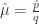

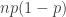
![\begin{array}{lcl} \mathbb{V}\left[\hat{\mu}\right] & = & \mathbb{V}\left[\frac{\hat{p}}{q}\right] \\ & = & \mathbb{V}\left[\frac{X}{nq}\right] \\ & = & \frac{1}{n^2q^2} \mathbb{V}\left[X\right] \\ & = & \frac{1}{n^2q^2} n p(1-p) \\ & = & \frac{1}{n^2q^2} n \mu q (1- \mu q) \\ & = & \frac{\mu (1- \mu q)}{nq} \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Blcl%7D+%5Cmathbb%7BV%7D%5Cleft%5B%5Chat%7B%5Cmu%7D%5Cright%5D+%26+%3D+%26+%5Cmathbb%7BV%7D%5Cleft%5B%5Cfrac%7B%5Chat%7Bp%7D%7D%7Bq%7D%5Cright%5D+%5C%5C+%26+%3D+%26+%5Cmathbb%7BV%7D%5Cleft%5B%5Cfrac%7BX%7D%7Bnq%7D%5Cright%5D+%5C%5C+%26+%3D+%26+%5Cfrac%7B1%7D%7Bn%5E2q%5E2%7D+%5Cmathbb%7BV%7D%5Cleft%5BX%5Cright%5D+%5C%5C+%26+%3D+%26+%5Cfrac%7B1%7D%7Bn%5E2q%5E2%7D+n+p%281-p%29+%5C%5C+%26+%3D+%26+%5Cfrac%7B1%7D%7Bn%5E2q%5E2%7D+n+%5Cmu+q+%281-+%5Cmu+q%29+%5C%5C+%26+%3D+%26+%5Cfrac%7B%5Cmu+%281-+%5Cmu+q%29%7D%7Bnq%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=333333&s=0&c=20201002)
Diese Varianz hängt nun von 

Vergleichen wir zum Beispiel zwei Regionen, eine mit 
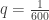

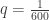

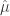

Wenn wir das Ganze stattdessen für die Region(en) mit 

Man könnte das auch noch statistisch etwas sauberer machen. Ich habe zum Beispiel ignoriert, dass man weiß, dass 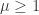

Man kann den “Dunkelzifferfaktor” (p/q) auch so schätzen:
X = Anzahl der wahren Infizierten vor 18 Tagen = Anzahl der an Corona gestorbenen heute / Mortalitätrate
Y = Anzahl der offiziell Infizierten for 18 Tagen
(p/q) = X/Y. Der Unsicherheitsfaktor bei dieser Schätzung kommt 1. vom Schätzfehler der Mortalitätsrate und 2. vom Schätzfehler der durchschnittlichen Zeit zwischen Infektion und Tod.
Sicher. Wenn man über die Mortalitätsrate in Österreich etwas wüsste, sowie auch über die Verteilung der Zeit zwischen Infektion und Tod, könnte man das auch mit einbeziehen, um noch genauere Schätzungen der Dunkelziffer zu bekommen.
Ich denke allerdings, dass es eher umgekehrt ist: dass wir aus einer guten Schätzung der Dunkelziffer dann eine gute Schätzung der Mortalitätsrate bekommen.
Ja aber es gibt Schätzungen der Mortalitätsrate aus anderen Ländern. Z.B. aus Island, wo auch eine zufällige Stichprobe getestet wurde.
Pingback: Coronavirus-Dunkelziffer: alternative Schätzung | Graz Economics Blog
Pingback: Die ökonomischen Konsequenzen des Coronovirus – ein genauerer Schätzer der Dunkelziffer | Graz Economics Blog
Pingback: Estimating the proportion of Corona cases with a random sample | Graz Economics Blog
Pingback: Estimating the proportion of Corona cases with a random sample – The Game Theory of Everyday Life